第 11 章 特型与泛型(1)
第 11 章 特型与泛型
计算机科学家倾向于处理非统一性结构(情形 1、情形 2、情形 3),而数学家则倾向于找一个统一的公理来管理整个体系。
——高德纳
编程领域的伟大发现之一,就是可以编写能对许多不同类型( 甚至是尚未发明的类型)的值进行操作的代码。下面是两个例子。
Vec<T>是泛型的:你可以创建任意类型值的向量,包括在你的程序中定义的连Vec的作者都不曾设想的类型。- 许多类型有
.write()方法,包括File和TcpStream。你的代码可以通过引用来获取任意写入器,并向它发送数据。你的代码不必关心写入器的类型。以后,如果有人添加了一种新型写入器,你的代码也能够直接支持。
当然,这种能力对 Rust 来说并不是什么新鲜事。这就是所谓的 多态性,在 20 世纪 70 年代,它是最新且最热门的编程语言技术。到了现在,多态性实际上已经成了通用技术。Rust 通过两个相关联的特性来支持多态:特型和泛型。许多程序员熟悉这些概念,但 Rust 受到 Haskell 类型类(typeclass)的启发,采用了一种全新的方式。
特型 是 Rust 体系中的接口或抽象基类。乍一看,它们和 Java 或 C# 中的接口差不多。写入字节的特型称为 std::io::Write,它在标准库中的定义开头部分是这样的:
trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()> { ... }
...
}
此特型还提供了几个方法,我们只展示了前 3 个。
File 和 TcpStream 这两个标准类型以及 Vec<u8> 都实现了 std::io::Write。这 3 种类型都提供了 .write()、 .flush() 等方法。使用写入器而不关心其具体类型的代码如下所示:
use std::io::Write;
fn say_hello(out: &mut dyn Write) -> std::io::Result<()> {
out.write_all(b"hello world\n")?;
out.flush()
}
out 的类型是 &mut dyn Write,意思是“对实现了 Write 特型的任意值的可变引用”。我们可以将任何此类值的可变引用传给 say_hello:
use std::fs::File;
let mut local_file = File::create("hello.txt")?;
say_hello(&mut local_file)?; // 正常
let mut bytes = vec![];
say_hello(&mut bytes)?; // 同样正常
assert_eq!(bytes, b"hello world\n");
本章展示特型的用法、工作原理,以及如何定义你自己的特型。其实,除了前面介绍的用法,特型还有很多其他用法:我们会使用特型为现有类型添加扩展方法,甚至可以在 str、 bool 等内置类型上添加;我们会解释为什么向类型添加特型不需要额外的内存,以及如何在不需要虚方法调用开销的情况下使用特型;我们会看到,某些内置特型其实是 Rust 为运算符重载和其他特性提供的语言级钩子;我们会介绍 Self 类型、关联函数和关联类型,这是 Rust 从 Haskell 中借来的三大特性,它们优雅地解决了其他语言中要通过变通和入侵才能解决的问题。
泛型 是 Rust 中多态的另一种形式。与 C++ 模板一样,泛型函数或泛型类型可以和不同类型的值一起使用:
/// 给定两个值,找出哪个更小
fn min<T: Ord>(value1: T, value2: T) -> T {
if value1 <= value2 {
value1
} else {
value2
}
}
此函数中的 <T: Ord> 表明 min 函数可以与实现了 Ord 特型的任意类型(任意有序类型) T 的参数一起使用。像这样的要求称为 限界,因为它对 T 可能的类型范围做了限制。编译器会针对你实际用到的每种类型 T 生成一份单独的机器码。
泛型和特型紧密相关:泛型函数会在限界中使用特型来阐明它能针对哪些类型的参数进行调用。因此,我们还会讨论 &mut dyn Write 和 <T: Write> 的相似之处、不同之处,以及如何在特型的这两种使用方式之间做出选择。
11.1 使用特型
特型是一种语言特性,我们 可以 说某类型支持或不支持某个特型。大多数情况下,特型代表着一种能力,即一个类型能做什么。
- 实现了
std::io::Write的值能写出一些字节。 - 实现了
std::iter::Iterator的值能生成一系列值。 - 实现了
std::clone::Clone的值能在内存中克隆自身。 - 实现了
std::fmt::Debug的值能用带有{:?}格式说明符的println!()打印出来。
这 4 个特型都是 Rust 标准库的一部分,许多标准类型实现了它们。
std::fs::File实现了Write特型,它能将一些字节写入本地文件。std::net::TcpStream能写入网络连接。Vec<u8>也实现了Write,对字节向量的每次.write()调用都会将一些数据追加到向量末尾。Range<i32>(表达式0..10的类型)实现了Iterator特型,一些与切片、哈希表等关联的迭代器类型同样实现了Iterator特型。- 大多数标准库类型实现了
Clone。没实现Clone的主要是一些像TcpStream这样的类型,因为它们代表的不仅仅是内存中的数据。 - 同样,大多数标准库类型支持
Debug。
关于特型方法有一条值得注意的规则:特型本身必须在作用域内。否则,它的所有方法都是不可见的:
let mut buf: Vec<u8> = vec![];
buf.write_all(b"hello")?; // 错误:没有名为`write_all`的方法
在这种情况下,编译器会打印出一条友好的错误消息,建议添加 use std::io::Write;,这确实可以解决问题:
use std::io::Write;
let mut buf: Vec<u8> = vec![];
buf.write_all(b"hello")?; // 正确
之所以 Rust 会有这条规则,是因为你可以使用特型为任意类型添加新方法——甚至是像 u32 和 str 这样的标准库类型(正如我们将在本章后面看到的那样)。而第三方 crate 也可以这样做。显然,这可能导致命名冲突。但是由于 Rust 会要求你导入自己想用的特型,因此 crate 可以放心地利用这种超能力。只有导入两个特型,才会发生冲突,将具有相同名称的方法添加到同一个类型中。这在实践中非常罕见。(如果确实遇到冲突,你可以使用带完全限定符的方法名明确写出自己想要的内容,本章后面会介绍。)
Clone 和 Iterator 的各个方法在没有任何特殊导入的情况下就能工作,因为默认情况下它们始终在作用域中:它们是标准库预导入的一部分,Rust 会把这些名称自动导入每个模块中。事实上,预导入主要就是一些精心挑选的特型。第 13 章会介绍其中的许多内容。
C++ 程序员和 C# 程序员可能已经看出来了,特型方法类似于虚方法。不过,特型方法的调用仍然很快,与任何其他方法调用一样快。一言以蔽之,这里没有多态。很明显, buf 一定是向量,而不可能是文件或网络连接。编译器可以生成对 Vec<u8>::write() 的简单调用,甚至可以内联该方法。(C++ 和 C# 通常也会这样做,不过有时会因为子类的缘故而无法做到。)只有通过 &mut dyn Write 调用时才会产生动态派发(也叫虚方法调用)的开销,类型上的 dyn 关键字指出了这一点。 dyn Write 叫作 特型对象,11.1.1 节会介绍特型对象的一些技术细节,以及它们与泛型函数的比较。
11.1.1 特型对象
在 Rust 中使用特型编写多态代码有两种方法:特型对象和泛型。我们将首先介绍特型对象,然后会在 11.1.2 节转向泛型。
Rust 不允许 dyn Write 类型的变量:
use std::io::Write;
let mut buf: Vec<u8> = vec![];
let writer: dyn Write = buf; // 错误:`Write`的大小不是常量
变量的大小必须是编译期已知的,而那些实现了 Write 的类型可以是任意大小。
如果你是 C# 程序员或 Java 程序员,可能会对此感到惊讶,但原因其实很简单。在 Java 中, OutputStream 类型(类似于 std::io::Write 的 Java 标准接口)的变量其实是对任何实现了 OutputStream 的对象的引用。它本身就是引用,无须显式说明。C# 和大多数其他语言中的接口也一样。
我们在 Rust 中也想这么做,但在 Rust 中,引用是显式的:
let mut buf: Vec<u8> = vec![];
let writer: &mut dyn Write = &mut buf; // 正确
对特型类型(如 writer)的引用叫作 特型对象。与任何其他引用一样,特型对象指向某个值,它具有生命周期,并且可以是可变或共享的。
特型对象的与众不同之处在于,Rust 通常无法在编译期间知道引用目标的类型。因此,特型对象要包含一些关于引用目标类型的额外信息。这仅供 Rust 自己在幕后使用:当你调用 writer.write(data) 时,Rust 需要使用类型信息来根据 *writer 的具体类型动态调用正确的 write 方法。你不能直接查询这些类型信息,Rust 也不支持从特型对象 &mut dyn Write 向下转型回像 Vec<u8> 这样的具体类型。
特型对象的内存布局
在内存中,特型对象是一个胖指针,由指向值的指针和指向表示该值类型的虚表的指针组成。因此,每个特型对象会占用两个机器字,如图 11-1 所示。
C++ 也有这种运行期类型信息,叫作 虚表 或 vtable。就像在 C++ 中一样,在 Rust 中,虚表只会在编译期生成一次,并由同一类型的所有对象共享。图 11-1 中深色部分展示的所有内容(包括虚表)都是 Rust 的私有实现细节。同样,这些都不是你可以直接访问的字段和数据结构。当你调用特型对象的方法时,该语言会自动使用虚表来确定要调用哪个实现。
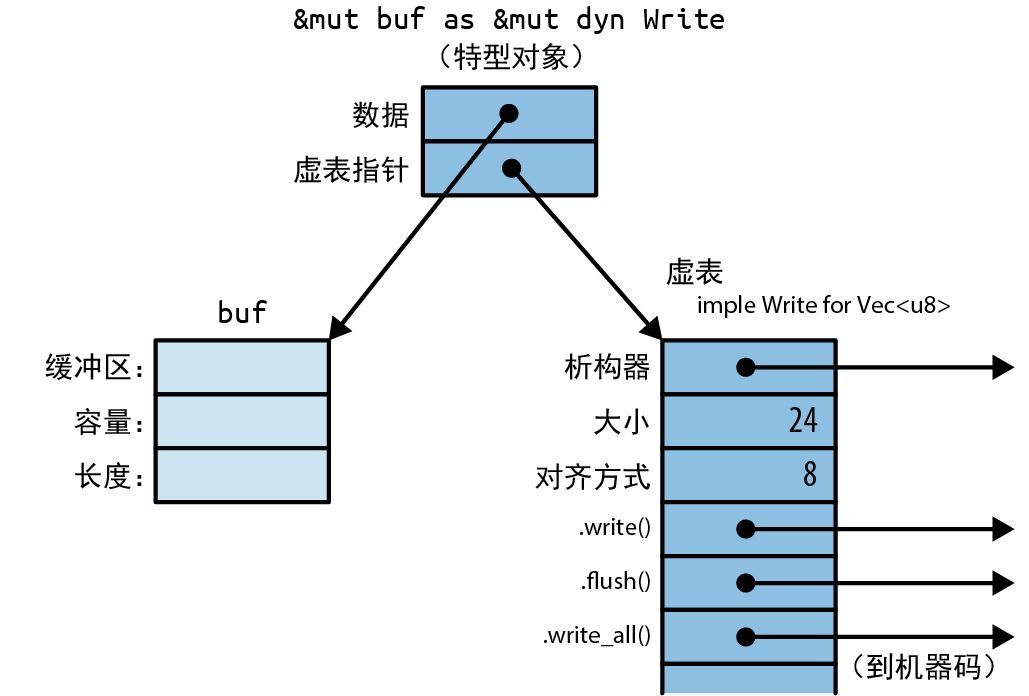
图 11-1:内存中的特型对象
经验丰富的 C++ 程序员可能会注意到 Rust 和 C++ 在内存使用上略有不同。在 C++ 中,虚表指针或 vptr 是作为结构体的一部分存储的,而 Rust 使用的是胖指针方案。结构体本身只包含自己的字段。这样一来,每个结构体就可以实现几十个特型而不必包含几十个 vptr 了。甚至连 i32 这样大小不足以容纳 vptr 的类型都可以实现特型。
Rust 在需要时会自动将普通引用转换为特型对象。这就是为什么我们能够在这个例子中把 &mut local_file 传给 say_hello:
let mut local_file = File::create("hello.txt")?;
say_hello(&mut local_file)?;
&mut local_file 的类型是 &mut File, say_hello 的参数类型是 &mut dyn Write。由于 File 也是一种写入器,因此 Rust 允许这样操作,它会自动将普通引用转换为特型对象。
同样,Rust 会愉快地将 Box<File> 转换为 Box<dyn Write>,这是一个拥有在堆中分配的写入器的值:
let w: Box<dyn Write> = Box::new(local_file);
和 &mut dyn Write 一样, Box<dyn Write> 也是一个胖指针,即包含写入器本身的地址和虚表的地址。其他指针类型(如 Rc<dyn Write>)同样如此。
这种转换是创建特型对象的唯一方法。编译器在这里真正做的事非常简单。在发生转换的地方,Rust 知道引用目标的真实类型(在本例中为 File),因此它只要加上适当的虚表的地址,把常规指针变成胖指针就可以了。
11.1.2 泛型函数与类型参数
本章在开头展示过一个以特型对象为参数的 say_hello() 函数。现在,让我们把该函数重写为泛型函数:
fn say_hello<W: Write>(out: &mut W) -> std::io::Result<()> {
out.write_all(b"hello world\n")?;
out.flush()
}
只有类型签名发生了变化:
fn say_hello(out: &mut dyn Write) // 普通函数
fn say_hello<W: Write>(out: &mut W) // 泛型函数
短语 <W: Write> 把函数变成了泛型形式。此短语叫作 类型参数。这意味着在这个函数的整个函数体中, W 都代表着某种实现了 Write 特型的类型。按照惯例,类型参数通常是单个大写字母。
W 代表哪种类型取决于泛型函数的使用方式:
say_hello(&mut local_file)?; // 调用say_hello::<File>
say_hello(&mut bytes)?; // 调用say_hello::<Vec<u8>>
当你将 &mut local_file 传给泛型函数 say_hello() 时,其实调用的是 say_hello::<File>()。Rust 会为此函数生成一份机器码,以调用 File::write_all() 方法和 File::flush() 方法。当你传入 &mut bytes 时,其实是在调用 say_hello::<Vec<u8>>()。Rust 会为这个版本的函数生成单独的机器码,以调用相应的 Vec<u8> 方法。在这两种情况下,Rust 都会从参数的类型推断出类型 W,这个过程叫作 单态化,编译器会自动处理这一切。
你总是可以明确写出类型参数:
say_hello::<File>(&mut local_file)?;
但一般无此必要,因为 Rust 通常可以通过查看参数来推断出类型参数。在这里, say_hello 泛型函数需要一个 &mut W 参数,我们向它传入了一个 &mut File,所以 Rust 断定 W = File。
如果你调用的泛型函数没有任何能提供有用线索的参数,则可能需要把它明确写出来:
// 调用无参数的泛型方法collect<C>()
let v1 = (0 .. 1000).collect(); // 错误:无法推断类型
let v2 = (0 .. 1000).collect::<Vec<i32>>(); // 正确
有时我们需要同一个类型参数的多种能力。如果想打印出向量中前十个最常用的值,那么就要让这些值是可打印的:
use std::fmt::Debug;
fn top_ten<T: Debug>(values: &Vec<T>) { ... }
但这还不够好。如果我们要确定哪些值是最常用的该怎么办呢?通常的做法是用这些值作为哈希表中的键。这意味着这些值还要支持 Hash 操作和 Eq 操作。 T 的类型限界必须包括这些特型,就像 Debug 一样。这种情况下就要使用 + 号语法:
use std::hash::Hash;
use std::fmt::Debug;
fn top_ten<T: Debug + Hash + Eq>(values: &Vec<T>) { ... }
有些类型实现了 Debug,有些类型实现了 Hash,有些类型支持 Eq,还有一些类型(如 u32 和 String)实现了所有这 3 个,如图 11-2 所示。
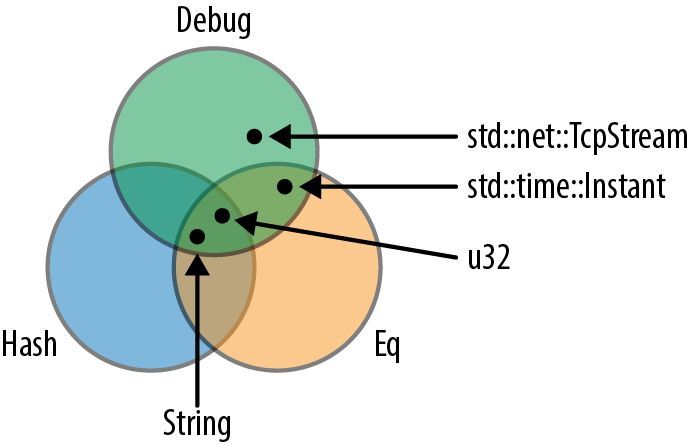
图 11-2:把类型集用作特型
类型参数也可能完全没有限界,但是如果没有为它指定任何限界,则无法对它做什么。你可以移动它,也可以将它放入一个 Box 或向量中。但也只能做这些了。
泛型函数可以有多个类型参数:
/// 在一个大型且分区的数据集上运行查询
/// 参见<http://research.google.com/archive/mapreduce.html>
fn run_query<M: Mapper + Serialize, R: Reducer + Serialize>(
data: &DataSet, map: M, reduce: R) -> Results
{ ... }
如本示例所示,限界可能会变得很长,让人眼花缭乱。Rust 使用关键字 where 提供了另一种语法:
fn run_query<M, R>(data: &DataSet, map: M, reduce: R) -> Results
where M: Mapper + Serialize,
R: Reducer + Serialize
{ ... }
类型参数 M 和 R 仍然放在前面声明,但限界移到了单独的行中。这种 where 子句也允许用于泛型结构体、枚举、类型别名和方法——任何允许使用限界的地方。
当然,替代 where 子句的最佳方案是保持简单:找到一种无须大量使用泛型就能编写程序的方式。
5.3.2 节中介绍了生命周期参数的语法。泛型函数可以同时具有生命周期参数和类型参数。生命周期参数要排在前面:
/// 返回对`candidates`中最接近`target`的点的引用
fn nearest<'t, 'c, P>(target: &'t P, candidates: &'c [P]) -> &'c P
where P: MeasureDistance
{
...
}
这个函数有两个参数,即 target 和 candidates。两者都是引用,但我们为它们赋予了不同的生命周期 't 和 'c(参见 5.3.6 节)。此外,该函数适用于实现了 MeasureDistance 特型的任意类型 P,因此可以在一个程序中将其用于 Point2d 值,而在另一个程序中将其用于 Point3d 值。
生命周期永远不会对机器码产生任何影响。如果对 nearest() 进行的两次调用使用了相同的类型 P 和不同的生命周期,那么就会调用同一个编译结果函数。只有不同的类型才会导致 Rust 编译出泛型函数的多个副本。
除了类型和生命周期,泛型函数也可以接受常量参数,就像 9.9 节中介绍过的 Polynomial 结构体:
fn dot_product<const N: usize>(a: [f64; N], b: [f64; N]) -> f64 {
let mut sum = 0.;
for i in 0..N {
sum += a[i] * b[i];
}
sum
}
在这里,短语 <const N: usize> 指出函数 dot_product 需要一个泛型参数 N,该参数必须是一个 usize。给定了 N,这个函数就会接受两个 [f64; N] 类型的参数,并将其对应元素的乘积相加。 N 与普通 usize 参数的区别是,你可以在 dot_product 的签名或函数体的类型中使用它。
与类型参数一样,你既可以显式提供常量参数,也可以让 Rust 推断它们。
// 显式提供`3`作为`N`的值
dot_product::<3>([0.2, 0.4, 0.6], [0., 0., 1.])
// 让Rust推断`N`必然是`2`
dot_product([3., 4.], [-5., 1.])
当然,函数并不是 Rust 中唯一的泛型代码。
-
9.7 节和 10.1.4 节已经介绍过泛型类型。
-
单独的方法也可以是泛型的,即使它并没有定义在泛型类型上。
impl PancakeStack { fn push<T: Topping>(&mut self, goop: T) -> PancakeResult<()> { goop.pour(&self); self.absorb_topping(goop) } } -
类型别名也可以是泛型的。
type PancakeResult<T> = Result<T, PancakeError>; -
本章在后面还会介绍一些泛型特型。
本节中介绍的特性(限界、 where 子句、生命周期参数等)可用于所有泛型语法项,而不仅仅是函数。
11.1.3 使用哪一个
关于是使用特型对象还是泛型代码的选择相当微妙。由于这两个特性都基于特型,因此它们有很多共同点。
当你需要一些混合类型值的集合时,特型对象是正确的选择。制作泛型沙拉在技术上是可行的:
trait Vegetable {
...
}
struct Salad<V: Vegetable> {
veggies: Vec<V>
}
然而,这是一种相当严格的设计:每一样沙拉都要完全由一种蔬菜组成。但毕竟众口难调。本书的一位作者就曾花 14 美元买过一份 Salad<IcebergLettuce>(球形生菜沙拉),那味道真是让人终生难忘。
怎样才能做出更好的沙拉呢?由于 Vegetable 的值可以有各种不同的大小,因此不能要求 Rust 接受 Vec<dyn Vegetable> 这种写法:
struct Salad {
veggies: Vec<dyn Vegetable> // 错误:`dyn Vegetable`的大小不是常量
}
解决方案是使用特型对象:
struct Salad {
veggies: Vec<Box<dyn Vegetable>>
}
每个 Box<dyn Vegetable> 都可以拥有任意类型的蔬菜,但 Box 本身具有适合存储在向量中的常量大小(两个指针)。虽然把盒子( Box)放进某个食物里这种隐喻怪怪的,但这正是我们想要的,这种方式同样适用于绘图应用程序中的形状、游戏中的怪物、网络路由器中的可插接路由算法等。
使用特型对象的另一个原因可能是想减少编译后代码的总大小。Rust 可能会不得不多次编译泛型函数,针对用到了它的每种类型各编译一次。而这可能会使二进制文件变大,这种现象在 C++ 圈子里叫作 代码膨胀。如今,内存资源充裕,大多数人可以不在乎代码大小,但确实仍然存在着某种受限环境。
除了像制作沙拉这种问题或是低资源环境之类的情况,与特型对象相比,泛型具有 3 个重要优势,因此在 Rust 中,泛型是更常见的选择。
第一个优势是速度。请注意泛型函数签名中缺少 dyn 关键字。因为你要在编译期指定类型,所以无论是显式写出还是通过类型推断,编译器都知道要调用哪个 write 方法。没有使用 dyn 关键字是因为这里不涉及特型对象(因此也不涉及动态派发)。
本章开头展示过的泛型函数 min() 运行起来与我们编写的单独的函数 min_u8、 min_i64、 min_string 等一样快。编译器可以像任何函数一样将其内联,因此在发布构建中,调用 min::<i32> 可能只有两三条指令。参数是常数的调用(如 min(5, 3))会更快:Rust 可以在编译期对其求值,因此根本没有运行期开销。
或者考虑这个泛型函数调用:
let mut sink = std::io::sink();
say_hello(&mut sink)?;
std::io::sink() 会返回类型为 Sink 的写入器,该写入器会悄悄地丢弃写入其中的所有字节。
当 Rust 为此生成机器码时,它可以生成调用 Sink::write_all 的代码,检查错误,然后调用 Sink::flush。这就是泛型函数体所要求做的。
Rust 还可以查看这些方法并注意到:
Sink::write_all()什么都不做;Sink::flush()什么都不做;- 这两种方法都不会返回错误。
简而言之,Rust 拥有完全优化此函数调用所需的全部信息。
这与特型对象的行为不同。在那种方式下,Rust 直到运行期才能知道特型对象指向什么类型的值。因此,即使你传递了 Sink,调用虚方法和检查错误的开销仍然存在。
泛型的第二个优势在于并不是每个特型都能支持特型对象。特型支持的几个特性(如关联函数)只适用于泛型:它们完全不支持特型对象。我们会在谈及这些特性时指出这一点。
泛型的第三个优势是它很容易同时指定具有多个特型的泛型参数限界,就像我们的 top_ten 函数要求它的 T 参数必须实现 Debug + Hash + Eq 那样。特型对象不能这样做:Rust 不支持像 &mut (dyn Debug + Hash + Eq) 这样的类型。(你可以使用本章稍后定义的子特型来解决这个问题,但有点儿复杂。)
11.2 定义与实现特型
定义特型很简单,给它一个名字并列出特型方法的类型签名即可。如果你正在编写游戏,那么可能会有这样的特型:
/// 角色、道具和风景的特型——游戏世界中可在屏幕上看见的任何东西
trait Visible {
/// 在给定的画布上渲染此对象
fn draw(&self, canvas: &mut Canvas);
/// 如果单击(x, y)时应该选中此对象,就返回true
fn hit_test(&self, x: i32, y: i32) -> bool;
}
要实现特型,请使用语法 impl TraitName for Type:
impl Visible for Broom {
fn draw(&self, canvas: &mut Canvas) {
for y in self.y - self.height - 1 .. self.y {
canvas.write_at(self.x, y, '|');
}
canvas.write_at(self.x, self.y, 'M');
}
fn hit_test(&self, x: i32, y: i32) -> bool {
self.x == x
&& self.y - self.height - 1 <= y
&& y <= self.y
}
}
请注意,这个 impl 包含 Visible 特型中每个方法的实现,再无其他。特型的 impl 代码中定义的一切都必须是真正属于此特型的,如果想添加一个辅助方法来支持 Broom::draw(),就必须在单独的 impl 块中定义它:
impl Broom {
/// 供下面的Broom::draw()使用的辅助函数
fn broomstick_range(&self) -> Range<i32> {
self.y - self.height - 1 .. self.y
}
}
这些辅助函数可以在特型的各个 impl 块中使用。
impl Visible for Broom {
fn draw(&self, canvas: &mut Canvas) {
for y in self.broomstick_range() {
...
}
...
}
...
}
11.2.1 默认方法
我们之前讨论的 Sink 写入器类型可以用几行代码来实现。首先,定义如下类型:
/// 一个会忽略你写入的任何数据的写入器
pub struct Sink;
Sink 是一个空结构体,因为我们不需要在其中存储任何数据。接下来,为 Sink 提供 Write 特型的实现:
use std::io::;
impl Write for Sink {
fn write(&mut self, buf: &[u8]) -> Result<usize> {
// 声称已成功写入了整个缓冲区
Ok(buf.len())
}
fn flush(&mut self) -> Result<()> {
Ok(())
}
}
迄今为止,这种写法和 Visible 特型非常相似。但我们看到 Write 特型中还有一个 write_all 方法:
let mut out = Sink;
out.write_all(b"hello world\n")?;
为什么 Rust 允许在未定义此方法的情况下 impl Write for Sink 呢?答案是标准库的 Write 特型定义中包含了对 write_all 的 默认实现:
trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()> {
let mut bytes_written = 0;
while bytes_written < buf.len() {
bytes_written += self.write(&buf[bytes_written..])?;
}
Ok(())
}
...
}
write 方法和 flush 方法是每个写入器必须实现的基本方法。写入器也可以自行实现 write_all,但如果没实现,就会使用前面展示过的默认实现。
你的自定义特型也可以包含一些使用同样语法的默认实现。
标准库中对默认方法最引人注目的应用场景是 Iterator 特型,它有一个必要方法 ( .next()) 和几十个默认方法。第 15 章会解释原因。
11.2.2 特型与其他人的类型
Rust 允许在任意类型上实现任意特型,但特型或类型二者必须至少有一个是在当前 crate 中新建的。
这意味着任何时候如果你想为任意类型添加一个方法,都可以使用特型来完成:
trait IsEmoji {
fn is_emoji(&self) -> bool;
}
/// 为内置的字符类型实现IsEmoji特型
impl IsEmoji for char {
fn is_emoji(&self) -> bool {
...
}
}
assert_eq!('$'.is_emoji(), false);
与任何其他特型方法一样,只有当 IsEmoji 在作用域内时这个新的 is_emoji 方法才是可见的。
这个特殊特型的唯一目的是向现有类型 char 中添加一个方法。这称为 扩展特型。当然,也可以通过 impl IsEmoji for str { ... } 等写法将此特型添加到其他类型中。
甚至可以使用一个泛型的 impl 块来一次性向整个类型家族添加扩展特型。这个特型可以在任意类型上实现:
use std::io::;
/// 能让你把HTML写入值里的特型
trait WriteHtml {
fn write_html(&mut self, html: &HtmlDocument) -> io::Result<()>;
}
为所有写入器实现特型会令其成为扩展特型,比如为所有 Rust 写入器添加一个方法:
/// 可以把HTML写入任何一个std::io writer
impl<W: Write> WriteHtml for W {
fn write_html(&mut self, html: &HtmlDocument) -> io::Result<()> {
...
}
}
impl<W: Write> WriteHtml for W 这一行的意思是“对于每个实现了 Write 的类型 W,这里有一个适用于 W 的 WriteHtml 实现”。
serde 库提供了一个很好的例子,表明在标准类型上实现用户定义的特型非常有用。 serde 是一个序列化库。也就是说,你可以使用 serde 将 Rust 数据结构写入磁盘,稍后再重新加载它们。这个库定义了一个特型 Serialize,它为该库支持的每种数据类型都提供了实现。因此在 serde 源代码中,有一些代码为 bool、 i8、 i16、 i32、数组类型和元组类型等内置类型,以及像 Vec 和 HashMap 这样的标准数据结构实现了 Serialize。
所有这些工作的成果,就是 serde 为这些类型添加了一个 .serialize() 方法。它可以这样使用:
use serde::Serialize;
use serde_json;
pub fn save_configuration(config: &HashMap<String, String>)
-> std::io::Result<()>
{
// 创建一个JSON序列化器以把数据写入文件
let writer = File::create(config_filename())?;
let mut serializer = serde_json::Serializer::new(writer);
// serde的`.serialize()`方法会完成剩下的工作
config.serialize(&mut serializer)?;
Ok(())
}
我们之前说过,在实现特型时,特型或类型二者必须至少有一个是在当前 crate 中新建的。这叫作 孤儿规则。它会帮助 Rust 确保特型的实现是唯一的。你的代码不能写成 impl Write for u8,因为 Write 和 u8 都是在标准库中定义的。如果 Rust 允许 crate 这样做,那么在不同的 crate 中可能会有多个 u8 的 Write 实现,而 Rust 并没有合理的方法来决定把哪个实现用于给定的方法调用。
(C++ 有一个类似的唯一性限制:单一定义规则。在典型的 C++ 流派中,除了一些最简单的情况,编译器不会强制执行此规则。如果你打破了此规则,就会得到未定义行为。)
11.2.3 特型中的 Self
特型可以用关键字 Self 作为类型。例如,标准库的 Clone 特型看起来是这样的(稍作简化):
pub trait Clone {
fn clone(&self) -> Self;
...
}
这里以 Self 作为返回类型意味着 x.clone() 的类型与 x 的类型相同,无论 x 是什么。如果 x 是 String,那么 x.clone() 的类型也必须是 String——而不能是 dyn Clone 或其他可克隆类型。
同样,如果我们定义如下特型
pub trait Spliceable {
fn splice(&self, other: &Self) -> Self;
}
并有两个实现:
impl Spliceable for CherryTree {
fn splice(&self, other: &Self) -> Self {
...
}
}
impl Spliceable for Mammoth {
fn splice(&self, other: &Self) -> Self {
...
}
}
那么在第一个 impl 中, Self 只是 CherryTree 的别名,而在第二个 impl 中,它是 Mammoth 的别名。这意味着可以将两棵樱桃树或两头猛犸象拼接在一起,但不表示可以创造出猛犸象和樱桃树的混合体。 self 的类型和 other 的类型必须匹配。
使用了 Self 类型的特型与特型对象不兼容:
// 错误:特型`Spliceable`不能用作特型对象
fn splice_anything(left: &dyn Spliceable, right: &dyn Spliceable) {
let combo = left.splice(right);
// ...
}
至于其原因,当我们深入研究特型的高级特性时还会一次又一次看到。Rust 会拒绝此代码,因为它无法对 left.splice(right) 这个调用进行类型检查。特型对象的全部意义恰恰在于其类型要到运行期才能知道。Rust 在编译期无从了解 left 和 right 是否为同一类型。
特型对象实际上是为最简单的特型类型而设计的,这些类型都可以使用 Java 中的接口或 C++ 中的抽象基类来实现。特型的高级特性很有用,但它们不能与特型对象共存,因为一旦有了特型对象,就会失去 Rust 对你的程序进行类型检查时所必需的类型信息。
现在,如果想要实现这种在遗传意义上不可能的拼接,可以设计一个对特型对象友好的特型:
pub trait MegaSpliceable {
fn splice(&self, other: &dyn MegaSpliceable) -> Box<dyn MegaSpliceable>;
}
此特型与特型对象兼容。对 .splice() 方法的调用可以通过类型检查,因为参数 other 的类型不需要匹配 self 的类型,只要这两种类型都是 MegaSpliceable 就可以了。
11.2.4 子特型
我们可以声明一个特型是另一个特型的扩展:
/// 游戏世界中的生物,既可以是玩家,也可以是
/// 其他小精灵、石像鬼、松鼠、食人魔等
trait Creature: Visible {
fn position(&self) -> (i32, i32);
fn facing(&self) -> Direction;
...
}
短语 trait Creature : Visible 表示所有生物都是可见的。每个实现了 Creature 的类型也必须实现 Visible 特型:
impl Visible for Broom {
...
}
impl Creature for Broom {
...
}
可以按任意顺序实现这两个特型,但是如果不为类型实现 Visible 只为其实现 Creature 则是错误的。在这里,我们说 Creature 是 Visible 的 子特型,而 Visible 是 Creature 的 超特型。
子特型与 Java 或 C# 中的子接口类似,因为用户可以假设实现了子特型的任何值也会实现其超特型。但是在 Rust 中,子特型不会继承其超特型的关联项,如果你想调用超特型的方法,那么仍然要保证每个特型都在作用域内。
事实上,Rust 的子特型只是对 Self 类型限界的简写。像下面这样的 Creature 定义与前面的定义完全等效。
trait Creature where Self: Visible {
...
}
11.2.5 类型关联函数
在大多数面向对象语言中,接口不能包含静态方法或构造函数,但特型可以包含类型关联函数,这是 Rust 对静态方法的模拟:
trait StringSet {
/// 返回一个新建的空集合
fn new() -> Self;
/// 返回一个包含`strings`中所有字符串的集合
fn from_slice(strings: &[&str]) -> Self;
/// 判断这个集合中是否包含特定的`string`
fn contains(&self, string: &str) -> bool;
/// 把一个字符串添加到此集合中
fn add(&mut self, string: &str);
}
每个实现了 StringSet 特型的类型都必须实现这 4 个关联函数。前两个函数,即 new() 和 from_slice(),不接受 self 参数。它们扮演着构造函数的角色。在非泛型代码中,可以使用 :: 语法调用这些函数,就像调用任何其他类型关联函数一样:
// 创建实现了StringSet的两个假想集合类型:
let set1 = SortedStringSet::new();
let set2 = HashedStringSet::new();
在泛型代码中,也可以使用 :: 语法,不过其类型部分通常是类型变量,如下面对 S::new() 的调用所示:
/// 返回`document`中不存在于`wordlist`中的单词集合
fn unknown_words<S: StringSet>(document: &[String], wordlist: &S) -> S {
let mut unknowns = S::new();
for word in document {
if !wordlist.contains(word) {
unknowns.add(word);
}
}
unknowns
}
与 Java 接口和 C# 接口一样,特型对象也不支持类型关联函数。如果想使用 &dyn StringSet 特型对象,就必须修改此特型,为每个未通过引用接受 self 参数的关联函数加上类型限界 where Self: Sized:
trait StringSet {
fn new() -> Self
where Self: Sized;
fn from_slice(strings: &[&str]) -> Self
where Self: Sized;
fn contains(&self, string: &str) -> bool;
fn add(&mut self, string: &str);
}
这个限界告诉 Rust,特型对象不需要支持特定的关联函数1。通过添加这些限界,就能把 StringSet 作为特型对象使用了。虽然特型对象仍不支持关联函数 new 或 from_slice,但你还是可以创建它们并用其调用 .contains() 和 .add()。同样的技巧也适用于其他与特型对象不兼容的方法。(我们暂且放弃对“为何这么改就行”的枯燥技术解释,但会在第 13 章介绍一下 Sized 特型,届时你就懂了。)
11.3 完全限定的方法调用
迄今为止,我们看到的所有调用特型方法的方式都依赖于 Rust 为你补齐了一些缺失的部分。假设你编写了以下内容:
"hello".to_string()
Rust 知道 to_string 指的是 ToString 特型的 to_string 方法(我们称之为 str 类型的实现)。所以这个游戏里有 4 个“玩家”:特型、特型的方法、方法的实现以及调用该实现时传入的值。很高兴我们不必在每次调用方法时都把它们完全写出来。但在某些情况下,你需要一种方式来准确表达你的意思。完全限定的方法调用符合此要求。
首先,要知道方法只是一种特殊的函数。下面两个调用是等效的:
"hello".to_string()
str::to_string("hello")
第二种形式看起来很像关联函数调用。尽管 to_string 方法需要一个 self 参数,但是仍然可以像关联函数一样调用。只需将 self 作为此函数的第一个参数传进去即可。
由于 to_string 是标准 ToString 特型的方法之一,因此你还可以使用另外两种形式:
ToString::to_string("hello")
<str as ToString>::to_string("hello")
所有这 4 种方法调用都会做同样的事情。大多数情况下,只要写 value.method() 就可以了。其他形式都是 限定 方法调用。它们要指定方法所关联的类型或特型。最后一种带有尖括号的形式,同时指定了两者,这就是 完全限定 的方法调用。
当你写下 "hello".to_string() 时,使用的是 . 运算符,你并没有确切说明要调用哪个 to_string 方法。Rust 有一个“方法查找”算法,它可以根据类型、隐式解引用等来解决这个问题。通过完全限定的调用,你可以准确地指出是哪一个方法,这在一些奇怪的情况下会有所帮助。
-
当两个方法具有相同的名称时。生拼硬凑的经典示例是
Outlaw(亡命之徒),它具有来自不同特型的两个.draw()方法,一个用于将其绘制在屏幕上,另一个用于犯罪。outlaw.draw(); // 错误:画(draw)在屏幕上还是拔出(draw)手枪? Visible::draw(&outlaw); // 正确:画在屏幕上 HasPistol::draw(&outlaw); // 正确:拔出手枪通常你可以对其中一个方法改名,但有时实在没法改。
-
当无法推断
self参数的类型时。let zero = 0; // 类型未指定:可能为`i8`、`u8`…… zero.abs(); // 错误:无法在有歧义的数值类型上调用方法`abs` i64::abs(zero); // 正确 -
将函数本身用作函数类型的值时。
let words: Vec<String> = line.split_whitespace() // 迭代器生成&str值 .map(ToString::to_string) // 正确 .collect(); -
在宏中调用特型方法时。第 21 章会对此进行解释。
完全限定语法也适用于关联函数。在 11.2.5 节中,我们编写了 S::new() 以在泛型函数中创建一个新集合。也可以写成 StringSet::new() 或 <S as StringSet>::new()。