第 5 章 引用
图书馆(库)1无法弥补个人(程序员)能力的不足。
——Mark Miller
迄今为止,我们看到的所有指针类型(无论是简单的 Box<T> 堆指针,还是 String 值和 Vec 值内部的指针)都是拥有型指针,这意味着当拥有者被丢弃时,它的引用目标也会随之消失。Rust 还有一种名为 引用(reference)的非拥有型指针,这种指针对引用目标的生命周期毫无影响。
事实上,影响是反过来的:引用的生命周期绝不能超出其引用目标。你的代码必须遵循这样的规则,即任何引用的生命周期都不可能超出它指向的值。为了强调这一点,Rust 把创建对某个值的引用的操作称为 借用(borrow)那个值:凡是借用,终须归还。
如果在读到“你的代码必须遵循这样的规则”这句话的时候不知道如何是好,那么你并非特例。引用本身确实没什么特别之处——说到底,它们只是地址而已。但用以让引用保持安全的规则,对 Rust 来说是一种创新,除了一些研究性语言,你不可能在其他编程语言中见到类似的规则。尽管这些规则是 Rust 中掌握起来最费心力的部分,但它们在防止经典的、常见的错误方面的覆盖度令人叹为观止,它们对多线程编程的影响也是革命性的。这又是 Rust 的“激进赌注”。
本章将介绍引用在 Rust 中的工作方式,我们会展开讲解引用、函数和自定义类型是如何通过包含生命周期信息来确保它们被安全使用的,并阐明这些努力为何能在编译期就避免一些常见类别的缺陷,而不必在运行期付出性能方面的代价。
5.1 对值的引用
假设我们要创建一张表格,列出文艺复兴时期某一特定类型的艺术家和他们的作品。Rust 的标准库包含一个哈希表类型,所以可以像下面这样定义我们的类型:
use std::collections::HashMap;
type Table = HashMap<String, Vec<String>>;
换句话说,这是一个将 String 值映射到 Vec<String> 值的哈希表,用于将艺术家的名字对应到他们作品名称的列表中。由于可以使用 for 循环遍历 HashMap 的条目,因此需要编写一个函数来打印 Table 的内容:
fn show(table: Table) {
for (artist, works) in table {
println!("works by {}:", artist);
for work in works {
println!(" {}", work);
}
}
}
构建和打印这个表格的代码也一目了然:
fn main() {
let mut table = Table::new();
table.insert("Gesualdo".to_string(),
vec!["many madrigals".to_string(),
"Tenebrae Responsoria".to_string()]);
table.insert("Caravaggio".to_string(),
vec!["The Musicians".to_string(),
"The Calling of St. Matthew".to_string()]);
table.insert("Cellini".to_string(),
vec!["Perseus with the head of Medusa".to_string(),
"a salt cellar".to_string()]);
show(table);
}
一切正常:
$ cargo run
Running `/home/jimb/rust/book/fragments/target/debug/fragments`
works by Gesualdo:
many madrigals
Tenebrae Responsoria
works by Cellini:
Perseus with the head of Medusa
a salt cellar
works by Caravaggio:
The Musicians
The Calling of St. Matthew
$
但是,如果你已经阅读过第 4 章关于“移动”的部分,就会对 show 这个函数的定义产生一些疑问。特别是, HashMap 不是 Copy 类型——也不可能是,因为它拥有能动态分配大小的表格。所以当程序调用 show(table) 时,整个结构就移动到了函数中,而变量 table 变成了未初始化状态。(而且它还会以乱序迭代其内容,所以如果你看到的顺序与这里不同,请不要担心,这是正常现象。)现在如果调用方代码试图使用 table,则会遇到麻烦:
...
show(table);
assert_eq!(table["Gesualdo"][0], "many madrigals");
Rust 会报错说 table 不再可用:
error: borrow of moved value: `table`
|
20 | let mut table = Table::new();
| --------- move occurs because `table` has type
| `HashMap<String, Vec<String>>`,
| which does not implement the `Copy` trait
...
31 | show(table);
| ----- value moved here
32 | assert_eq!(table["Gesualdo"][0], "many madrigals");
| ^^^^^ value borrowed here after move
事实上,如果查看 show 的定义,你会发现外层的 for 循环获取了哈希表的所有权并完全消耗掉了,并且内部的 for 循环对每个向量执行了相同的操作。(之前我们在 4.2.3 节的示例中看到过这种行为。)由于移动的语义特点,我们只是想把它打印出来,却完全破坏了整个结构。Rust,你可“真行”!
处理这个问题的正确方式是使用引用。引用能让你在不影响其所有权的情况下访问值。引用分为以下两种。
- 共享引用 允许你读取但不能修改其引用目标。但是,你可以根据需要同时拥有任意数量的对特定值的共享引用。表达式
&e会产生对e值的共享引用,如果e的类型为T,那么&e的类型就是&T,读作“refT”。共享引用是Copy类型。 - 可变引用 允许你读取和修改值。但是,一旦一个值拥有了可变引用,就无法再对该值创建其他任何种类的引用了。表达式
&mut e会产生一个对e值的可变引用,可以将其类型写成&mut T,读作“ref muteT”。可变引用不是Copy类型。
可以将共享引用和可变引用之间的区别视为在编译期强制执行“多重读取”或“单一写入”规则的一种手段。事实上,这条规则不仅适用于引用,也适用于所引用值的拥有者。只要存在对一个值的共享引用,即使是它的拥有者也不能修改它,该值会被锁定。当 show 正在使用 table 时,没有人可以修改它。类似地,如果有某个值的可变引用,那么它就会独占对该值的访问权,在可变引用消失之前,即使拥有者也根本无法使用该值。事实证明,让共享和修改保持完全分离对于内存安全至关重要,本章会在稍后内容中讨论原因。
我们示例中的打印函数不需要修改表格,只需读取其内容即可。所以调用者可以向它传递一个对表的共享引用,如下所示:
show(&table);
引用是非拥有型指针,因此 table 变量仍然是整个结构的拥有者, show 刚刚只是借用了一会儿。当然,我们需要调整 show 的定义来匹配它,但必须仔细观察才能看出差异:
fn show(table: &Table) {
for (artist, works) in table {
println!("works by {}:", artist);
for work in works {
println!(" {}", work);
}
}
}
show 中的 table 参数的类型已从 Table 变成了 &Table:现在不再按值传入 table(那样会将所有权转移到函数中),而是传入了共享引用。这是代码上的唯一变化。但是当我们深入函数体了解其工作原理时,这会有怎样的影响呢?
在以前的版本中,外部 for 循环获取了此 HashMap 的所有权并消耗掉了它,但在新版本中,它收到了对 HashMap 的共享引用。迭代中对 HashMap 的共享引用就是对每个条目的键和值的共享引用: artist 从 String 变成了 &String,而 works 从 Vec<String> 变成了 &Vec<String>。
内层循环也有类似的改变。迭代中对向量的共享引用就是对其元素的共享引用,因此 work 现在是 &String。此函数的任何地方都没有发生过所有权转移,它只会传递非拥有型引用。
现在,如果想写一个函数来按字母顺序排列每位艺术家的作品,那么只通过共享引用是不够的,因为共享引用不允许修改。而这个排序函数需要对表进行可变引用:
fn sort_works(table: &mut Table) {
for (_artist, works) in table {
works.sort();
}
}
于是我们需要传入一个:
sort_works(&mut table);
这种可变借用使 sort_works 能够按照向量的 sort 方法的要求读取和修改此结构。
当通过将值的所有权转移给函数的方式将这个值传给函数时,就可以说 按值 传递了它。如果改为将值的引用传给函数,就可以说 按引用 传递了它。例如,我们刚刚修复了 show 函数,将其改为按引用而不是按值接受 table。许多语言中也有这种区分,但在 Rust 中这尤为重要,因为它阐明了所有权是如何受到影响的。
5.2 使用引用
前面的示例展示了引用的一个非常典型的用途:允许函数在不获取所有权的情况下访问或操纵某个结构。但引用比这要灵活得多,下面我们通过一些示例来更详细地了解引用的用法。
5.2.1 Rust 引用与 C++ 引用
如果熟悉 C++ 中的引用,你就会知道它们确实与 Rust 引用有某些共同点。最重要的是,它们都只是机器级别的地址。但在实践中,Rust 的引用会给人截然不同的感觉。
在 C++ 中,引用是通过类型转换隐式创建的,并且是隐式解引用的:
// C++代码!
int x = 10;
int &r = x; // 初始化时隐式创建引用
assert(r == 10); // 对r隐式解引用,以查看x的值
r = 20; // 把20存入x,r本身仍然指向x
在 Rust 中,引用是通过 & 运算符显式创建的,同时要用 * 运算符显式解引用:
// 从这里开始回到Rust代码
let x = 10;
let r = &x; // &x是对x的共享引用
assert!(*r == 10); // 对r显式解引用
要创建可变引用,可以使用 &mut 运算符:
let mut y = 32;
let m = &mut y; // &muty是对y的可变引用
*m += 32; // 对m显式解引用,以设置y的值
assert!(*m == 64); // 来看看y的新值
也许你还记得,当我们修复 show 函数以通过引用而非值来获取艺术家表格时,并未使用过 * 运算符。这是为什么呢?
由于引用在 Rust 中随处可见,因此 . 运算符就会按需对其左操作数隐式解引用:
struct Anime { name: &'static str, bechdel_pass: bool }
let aria = Anime { name: "Aria: The Animation", bechdel_pass: true };
let anime_ref = &aria;
assert_eq!(anime_ref.name, "Aria: The Animation");
// 与上一句等效,但把解引用过程显式地写了出来
assert_eq!((*anime_ref).name, "Aria: The Animation");
show 函数中使用的 println! 宏会展开成使用 . 运算符的代码,因此它也能利用这种隐式解引用的方式。
在进行方法调用时, . 运算符也可以根据需要隐式借用对其左操作数的引用。例如, Vec 的 sort 方法就要求参数是对向量的可变引用,因此这两个调用是等效的:
let mut v = vec![1973, 1968];
v.sort(); // 隐式借用对v的可变引用
(&mut v).sort(); // 等效,但是更烦琐
简而言之,C++ 会在引用和左值(引用内存中位置的表达式)之间隐式转换,并且这种转换会出现在任何需要转换的地方,而在 Rust 中要使用 & 运算符和 * 运算符来创建引用(借用)和追踪引用(解引用),不过 . 运算符不需要做这种转换,它会隐式借用和解引用。
5.2.2 对引用变量赋值
把引用赋值给某个引用变量会让该变量指向新的地方:
let x = 10;
let y = 20;
let mut r = &x;
if b { r = &y; }
assert!(*r == 10 || *r == 20);
引用 r 最初指向 x。但如果 b 为 true,则代码会把它改为指向 y,如图 5-1 所示。
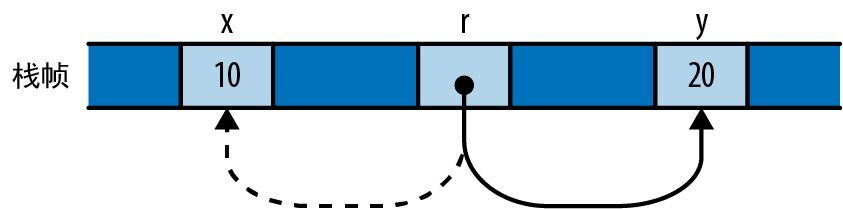
图 5-1:引用 r 现在指向 y 而不再是 x
乍一看,这种行为可能太显而易见,不值一提:现在 r 当然会指向 y,因为我们在其中存储了 &y。但特意指出这一点是因为 C++ 引用的行为与此截然不同:如前所述,在 C++ 中对引用赋值会将新值存储在其引用目标中而非指向新值。C++ 的引用一旦完成初始化,就无法再指向别处了。
5.2.3 对引用进行引用
Rust 允许对引用进行引用:
struct Point { x: i32, y: i32 }
let point = Point { x: 1000, y: 729 };
let r: &Point = &point;
let rr: &&Point = &r;
let rrr: &&&Point = &rr;
(为了让讲解更清晰,我们标出了引用的类型,但你可以省略它们,这里没有什么是 Rust 无法自行推断的。) . 运算符会追踪尽可能多层次的引用来找到它的目标:
assert_eq!(rrr.y, 729);
在内存中,引用的排列方式如图 5-2 所示。
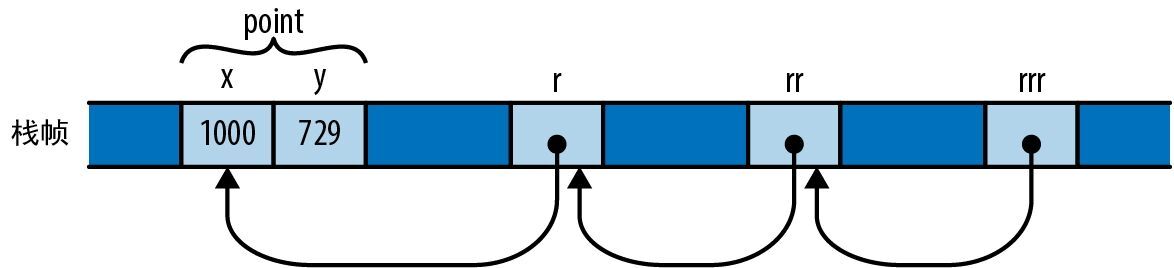
图 5-2:对引用的引用链
在这里,表达式 rrr.y 根据 rrr 的类型的指引遍历了 3 层引用才取到相应 Point 的 y 字段。
5.2.4 比较引用
就像 . 运算符一样,Rust 的比较运算符也能“看穿”任意数量的引用:
let x = 10;
let y = 10;
let rx = &x;
let ry = &y;
let rrx = ℞
let rry = &ry;
assert!(rrx <= rry);
assert!(rrx == rry);
虽然 rrx 和 rry 指向的是不同的值( rx 和 ry),这里的断言最终仍然会成功,因为 == 运算符会追踪所有引用并对它们的最终目标 x 和 y 进行比较。这几乎总是你期望的行为,尤其是在编写泛型函数时。如果你真想知道两个引用是否指向同一块内存,可以使用 std::ptr::eq,它会将两者作为地址进行比较:
assert!(rx == ry); // 它们引用的目标值相等
assert!(!std::ptr::eq(rx, ry)); // 但所占据的地址(自身的值)不同
但要注意,比较运算符的操作数(包括引用型操作数)必须具有完全相同的类型。
assert!(rx == rrx); // 错误:`&i32`与`&&i32`的类型不匹配
assert!(rx == *rrx); // 这样没问题
5.2.5 引用永不为空
Rust 的引用永远都不会为空。与 C 的 NULL 或 C++ 的 nullptr 类似的东西是不存在的。引用没有默认初始值(在初始化之前不能使用任何变量,无论其类型如何),并且 Rust 不会将整数转换为引用(在 unsafe 代码外)。因此,不能将 0 转换成引用。
C 代码和 C++ 代码通常会使用空指针来指示值的缺失:当可用内存充足时, malloc 函数会返回指向新内存块的指针,否则会返回 nullptr。在 Rust 中,如果需要用一个值来表示对某个“可能不存在”事物的引用,请使用类型 Option<&T>。在机器码级别,Rust 会将 None 表示为空指针,将 Some(r) 表示为非零地址(其中 r 是 &T 型的值),因此 Option<&T> 与 C 或 C++ 中的可空指针一样高效,但更安全:它的类型要求你在使用之前必须检查它是否为 None。
5.2.6 借用任意表达式结果值的引用
C 和 C++ 只允许将 & 运算符应用于某些特定种类的表达式,而 Rust 允许借用任意种类的表达式结果值的引用:
fn factorial(n: usize) -> usize {
(1..n+1).product()
}
let r = &factorial(6);
// 数学运算符可以“看穿”一层引用
assert_eq!(r + &1009, 1729);
在这种情况下,Rust 会创建一个匿名变量来保存此表达式的值,并让该引用指向它。这个匿名变量的生命周期取决于你对引用做了什么。
- 在
let语句中,如果立即将引用赋值给某个变量(或者使其成为立即被赋值的某个结构体或数组的一部分),那么 Rust 就会让匿名变量存在于let初始化此变量期间。在前面的示例中,Rust 就会对r的引用目标这样做。 - 否则,匿名变量会一直存续到所属封闭语句块的末尾。在我们的示例中,为保存
1009而创建的匿名变量只会存续到assert_eq!语句的末尾。
如果你习惯于使用 C 或 C++,那么这可能听起来很容易出错。但别忘了,Rust 永远不会让你写出可能生成悬空引用的代码。只要引用可能在匿名变量的生命周期之外被使用,Rust 就一定会在编译期间报告问题,然后你就可以通过将引用保存在具有适当生命周期的命名变量中来修复代码。
5.2.7 对切片和特型对象的引用
迄今为止,我们展示的引用全都是简单地址。但是,Rust 还包括两种 胖指针,即携带某个值地址的双字值,以及要正确使用该值所需的某些额外信息。
对切片的引用就是一个胖指针,携带着此切片的起始地址及其长度。第 3 章详细讲解过切片。
Rust 的另一种胖指针是 特型对象,即对实现了指定特型的值的引用。特型对象会携带一个值的地址和指向适用于该值的特型实现的指针,以便调用特型的方法。11.1.1 节会详细介绍特型对象。
除了会携带这些额外数据,切片和特型对象引用的行为与本章中已展示过的其他引用是一样的:它们并不拥有自己的引用目标、它们的生命周期也不允许超出它们的引用目标、它们可能是可变的或共享的,等等。
5.3 引用安全
正如前面介绍过的那样,引用看起来很像 C 或 C++ 中的普通指针。但普通指针是不安全的,Rust 又如何保持对引用的全面控制呢?或许了解规则的最佳方式就是尝试打破规则。
为了传达基本思想,我们将从最简单的案例开始,展示 Rust 如何确保在单个函数体内正确使用引用。然后我们会看看如何在函数之间传递引用并将它们存储到数据结构中。这需要为函数和数据类型提供 生命周期参数(稍后会对其进行解释)。最后我们会介绍 Rust 提供的一些简写形式,以简化常见的使用模式。在整个过程中,我们将展示 Rust 如何找出损坏的代码,并不时提出解决方案。
5.3.1 借用局部变量
这是一个非常浅显的案例。你不能借用对局部变量的引用并将其移出变量的作用域:
{
let r;
{
let x = 1;
r = &x;
}
assert_eq!(*r, 1); // 错误:试图读取`x`所占用的内存
}
Rust 编译器会拒绝此程序,并显示详细的错误消息:
error: `x` does not live long enough
|
7 | r = &x;
| ^^ borrowed value does not live long enough
8 | }
| - `x` dropped here while still borrowed
9 | assert_eq!(*r, 1); // 错误:试图读取`x`所占用的内存
10 | }
Rust 报错说 x 只能存续至内部块的末尾,而引用( r)会一直存续至外部块的末尾,这就让它成了悬空指针,这是被禁止的。
虽然对人类读者来说这个程序很明显是错误的,但还是值得研究一下 Rust 本身如何得出的这个结论。即使是这么简单的例子,也能展示出 Rust 用来检查更复杂代码的一些逻辑工具。
Rust 会尝试为程序中的每个引用类型分配一个 生命周期,以表达根据其使用方式应施加的约束。生命周期是程序的一部分,可以确保引用在下列位置都能被安全地使用:语句中、表达式中、某个变量的作用域中等。生命周期完全是 Rust 在编译期虚构的产物。在运行期,引用只是一个地址,它的生命周期只是其类型的一部分,不存在运行期表示。
在这个例子中,我们要分析 3 个生命周期之间的关系。变量 r 和 x 都有各自的生命周期,从它们被初始化的时间点一直延续到足以让编译器断定不再使用它们的时间点。第三个生命周期是引用类型,即借用了 x 并存储在 r 中的引用类型。
这里有一个显而易见的约束:如果有一个变量 x,那么对 x 的引用的生命周期不能超出 x 本身,如图 5-3 所示。

图 5-3: &x 的容许生命周期
当 x 超出作用域时,其引用将是一个悬空指针。为此,我们说变量的生命周期必须 涵盖 借用过它的引用的生命周期。
这是另一个约束:如果将引用存储在变量 r 中,则引用类型必须在变量 r 从初始化到最后一次使用的整个生命周期内都可以访问,如图 5-4 所示。

图 5-4:存储在 r 中的引用的容许生命周期
如果引用的生命周期不能至少和变量 r 一样长,那么在某些时候变量 r 就会变成悬空指针。为此,我们说引用的生命周期必须涵盖变量 r 的生命周期。
第一个约束限制了引用的生命周期可以有多大,而第二个约束则限制了它可以有多小。Rust 会尝试找出能让每个引用都满足这两个约束的生命周期。然而我们的示例中并不存在这样的生命周期,如图 5-5 所示。

图 5-5:引用的生命周期,其各项约束存在矛盾
现在来看一个不一样的例子,这次就行得通了。还是同样的约束:引用的生命周期必须包含在 x 中,但也要完全涵盖 r 的生命周期。因为现在 r 的生命周期变小了,所以会有一个生命周期满足这些约束,如图 5-6 所示。
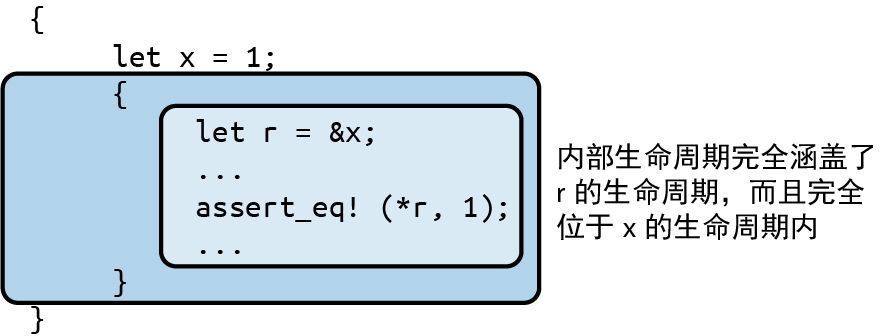
图 5-6:引用的生命周期涵盖了 r 的生命周期且同时位于 x 的作用域内
当你借用大型数据结构中某些部分(比如向量的元素)的引用时,会自然而然地应用这些规则:
let v = vec![1, 2, 3];
let r = &v[1];
由于 v 拥有一个向量,此向量又拥有自己的元素,因此 v 的生命周期必须涵盖 &v[1] 引用类型的生命周期。类似地,如果将一个引用存储于某个数据结构中,则此引用的生命周期也必须涵盖那个数据结构的生命周期。如果构建一个由引用组成的向量,则所有这些引用的生命周期都必须涵盖拥有该向量的变量的生命周期。
这是 Rust 用来处理所有代码的过程的本质。引入更多的语言特性(比如数据结构和函数调用),必然会引入一些全新种类的约束,但基本原则保持不变:首先,要了解程序中使用各种引用的方式带来的约束;其次,找出能同时满足这些约束的生命周期。这与 C 和 C++ 程序员不得不人工担负的过程没有多大区别,唯一的区别是 Rust 知道这些规则并会强制执行。
5.3.2 将引用作为函数参数
当我们传递对函数的引用时,Rust 要如何确保函数能安全地使用它呢?假设我们有一个函数 f,它会接受一个引用并将其存储在全局变量中。我们需要对此进行一些修改,下面是第一个版本:
// 这段代码有一系列问题,无法编译
static mut STASH: &i32;
fn f(p: &i32) { STASH = p; }
在 Rust 中,全局变量的等价物称为 静态变量(static):它是在程序启动时就会被创建并一直存续到程序终止时的值。(与任何其他声明一样,Rust 的模块系统会控制静态变量在何处可见,因此这只表示它们的生命周期是“全局”的,并不表示它们全局可见。)第 8 章会介绍静态变量,现在我们只讲一下刚才展示的代码违反了哪些规则。
- 每个静态变量都必须初始化。
- 可变静态变量本质上不是线程安全的(毕竟,任何线程都可以随时访问静态变量),即使在单线程的程序中,它们也可能成为一些另类可重入性问题的牺牲品。由于这些原因,你只能在
unsafe块中访问可变静态变量。在这个例子中,我们并不关心那几个具体问题,所以只是把可变静态变量扔到了一个unsafe块中。
经过这些修改,现在我们有了以下内容:
static mut STASH: &i32 = &128;
fn f(p: &i32) { // 仍然不够理想
unsafe {
STASH = p;
}
}
就快完工了。要查看剩下的问题,就要把 Rust 替我们省略的一些代码写出来。此处所写的 f 的签名实际上是以下内容的简写:
fn f<'a>(p: &'a i32) { ... }
这里,生命周期 'a(读作“tick A”)是 f 的 生命周期参数。 <'a> 的意思是“对于任意生命周期 'a”,因此当我们编写 fn f<'a>(p: &'a i32) 时,就定义了一个函数,该函数能接受对具有任意生命周期 'a 的 i32 型引用。
因为必须允许 'a 是任意生命周期,所以如果它是可能的最小生命周期(一个恰好涵盖对 f 调用的生命周期),那么问题就能轻易解决。接下来赋值语句就成了争论的焦点:
STASH = p;
由于 STASH 会存续在程序的整个执行过程中,因此它所持有的引用类型必须具有等长的生命周期,Rust 将此称为 'static 生命周期。但是指向 p 的引用的生命周期是 'a,它可以是任何能涵盖对 f 调用的生命周期。所以,Rust 拒绝了我们的代码:
error: explicit lifetime required in the type of `p`
|
5 | STASH = p;
| ^ lifetime `'static` required
在这个时间点,很明显我们的函数不能接受任意引用作为参数。但正如 Rust 指出的那样,它应当接受具有 'static 生命周期的引用:在 STASH 中存储这样的引用不会创建悬空指针。事实上,下面的代码就编译得很好:
static mut STASH: &i32 = &10;
fn f(p: &'static i32) {
unsafe {
STASH = p;
}
}
这一次, f 的签名指出 p 必须是生命周期为 'static 的引用,因此将其存储在 STASH 中不会再有任何问题。我们只能用对其他静态变量的引用来调用 f,但这是唯一一种肯定不会让 STASH 悬空的方式。所以可以像下面这样写:
static WORTH_POINTING_AT: i32 = 1000;
f(&WORTH_POINTING_AT);
由于 WORTH_POINTING_AT 是静态变量,因此 &WORTH_POINTING_AT 的类型是 &'static i32,将该类型传给 f 是安全的。
不过,可以退后一步,来看看在修改成正确方法时, f 的签名发生了哪些变化:原来的 f(p: &i32) 最后变成了 f(p: &'static i32)。换句话说,我们无法编写在全局变量中潜藏一个引用却不在函数签名中明示该意图的函数。在 Rust 中,函数的签名总会揭示出函数体的行为。
相反,如果确实看到一个带有 g(p: &i32) 签名的函数(或者带着生命周期写成 g<'a>(p: &'a i32)),那么就可以肯定它 没有 将其参数 p 藏在任何超出此调用点的地方。无须查看 g 的具体定义,签名本身就可以告诉我们 g 用它的参数能做什么,不能做什么。当你尝试为函数调用建立安全保障时,这一认知会非常有价值。
5.3.3 把引用传给函数
我们刚刚揭示了函数签名与其函数体的关系,下面再来看一下函数签名与其调用者的关系。假设你有以下代码:
// 这个函数可以简写为fn g(p: &i32),但这里还是把它的生命周期写出来了
fn g<'a>(p: &'a i32) { ... }
let x = 10;
g(&x);
只要看看 g 的签名,Rust 就知道它不会将 p 保存在生命周期可能超出本次调用的任何地方:包含本次调用的任何生命周期都必须符合 'a 的要求。所以 Rust 为 &x 选择了尽可能短的生命周期,即调用 g 时的生命周期。这满足所有约束:它的生命周期不会超出 x,并且会涵盖对 g 的完整调用。所以这段代码通过了审核。
请注意,虽然 g 有一个生命周期参数 'a,但调用 g 时并不需要提及它。只要在定义函数和类型时关心生命周期参数就够了,使用它们时,Rust 会为你推断生命周期。
如果试着将 &x 传给之前要求其参数存储在静态变量中的函数 f 会怎样呢?
fn f(p: &'static i32) { ... }
let x = 10;
f(&x);
这无法编译:引用 &x 的生命周期不能超出 x,但通过将它传给 f,又限制了它必须至少和 'static 一样长。没办法做到两全其美,所以 Rust 只好拒绝了这段代码。
5.3.4 返回引用
函数通常会接收某个数据结构的引用,然后返回对该结构的某个部分的引用。例如,下面是一个函数,它会返回对切片中最小元素的引用:
// v应该至少有一个元素
fn smallest(v: &[i32]) -> &i32 {
let mut s = &v[0];
for r in &v[1..] {
if *r < *s { s = r; }
}
s
}
我们依惯例在该函数的签名中省略了生命周期。当函数以单个引用作为参数并返回单个引用时,Rust 会假定两者具有相同的生命周期。如果把生命周期明确地写出来,则能看得更清楚:
fn smallest<'a>(v: &'a [i32]) -> &'a i32 { ... }
假设我们是这样调用 smallest 的:
let s;
{
let parabola = [9, 4, 1, 0, 1, 4, 9];
s = smallest(¶bola);
}
assert_eq!(*s, 0); // 错误:指向了已被丢弃的数组的元素
从 smallest 的签名可以看出它的参数和返回值必须具有相同的生命周期 'a。在我们的调用中,参数 ¶bola 的生命周期不得超出 parabola 本身,但 smallest 的返回值的生命周期必须至少和 s 一样长。生命周期 'a 不可能同时满足这两个约束,因此 Rust 拒绝执行这段代码:
error: `parabola` does not live long enough
|
11 | s = smallest(¶bola);
| -------- borrow occurs here
12 | }
| ^ `parabola` dropped here while still borrowed
13 | assert_eq!(*s, 0); // 错误:指向了已被丢弃的数组的元素
| - borrowed value needs to live until here
14 | }
移动 s,让其生命周期完全包含在 parabola 内就可以解决问题:
{
let parabola = [9, 4, 1, 0, 1, 4, 9];
let s = smallest(¶bola);
assert_eq!(*s, 0); // 很好:parabola仍然“活着”
}
函数签名中的生命周期能让 Rust 评估你传给函数的引用与函数返回的引用之间的关系,并确保安全地使用它们。
5.3.5 包含引用的结构体
Rust 如何处理存储在数据结构中的引用呢?下面仍然是之前那个出错的程序,但这次我们将引用“藏”在了结构体中:
// 这无法编译
struct S {
r: &i32
}
let s;
{
let x = 10;
s = S { r: &x };
}
assert_eq!(*s.r, 10); // 错误:从已被丢弃的`x`中读取
Rust 对引用的安全约束不会因为我们将引用“藏”在结构体中而神奇地消失。无论如何,这些约束最终也必须应用在 S 上。的确,Rust 提出了质疑:
error: missing lifetime specifier
|
7 | r: &i32
| ^ expected lifetime parameter
每当一个引用类型出现在另一个类型的定义中时,必须写出它的生命周期。可以这样写:
struct S {
r: &'static i32
}
这表示 r 只能引用贯穿程序整个生命周期的 i32 值,这种限制太严格了。还有一种方法是给类型指定一个生命周期参数 'a 并将其用在 r 上:
struct S<'a> {
r: &'a i32
}
现在 S 类型有了一个生命周期,就像引用类型一样。你创建的每个 S 类型的值都会获得一个全新的生命周期 'a,它会受到该值的使用方式的限制。你存储在 r 中的任何引用的生命周期最好都涵盖 'a,并且 'a 必须比存储在 S 中的任何内容的生命周期都要长。
回到前面的代码,表达式 S { r: &x } 创建了一个新的 S 值,其生命周期为 'a。当你将 &x 存储在 r 字段中时,就将 'a 完全限制在了 x 的生命周期内部。
赋值语句 s = S { ... } 会将此 S 存储在一个变量中,该变量的生命周期会延续到示例的末尾,这种限制决定了 'a 比 s 的生命周期更长。现在 Rust 遇到了与之前一样矛盾的约束: 'a 的生命周期不能超出 x,但必须至少和 s 一样长。因为找不到两全其美的生命周期,所以 Rust 拒绝执行该代码。一场灾难提前化解了。
如果将具有生命周期参数的类型放置在其他类型中会怎样呢?
struct D {
s: S // 不合格
}
Rust 提出了质疑,就像试图在 S 中放置一个引用而未指定其生命周期一样:
error: missing lifetime specifier
|
8 | s: S // 不合格
| ^ expected named lifetime parameter
|
不能在这里省略 S 的生命周期参数:Rust 需要知道 D 的生命周期和其引用的 S 的生命周期之间是什么关系,以便对 D 进行与“ S 和普通引用”一样的检查。
可以给 s 一个 'static 生命周期。这样没问题:
struct D {
s: S<'static>
}
使用这种定义, s 字段只能借用存续于整个程序执行过程中的值。这会带来一定的限制,但它确实表明 D 不可能借用局部变量,而 D 本身的生命周期并没有特殊限制。
来自 Rust 的错误消息其实建议了另一种方法,这种方法更通用:
help: consider introducing a named lifetime parameter
|
7 | struct D<'a> {
8 | s: S<'a>
|
这一次,为 D 提供生命周期参数并将其传给 S:
struct D<'a> {
s: S<'a>
}
通过获取生命周期参数 'a 并在 s 的类型中使用它,我们允许 Rust 将 D 值的生命周期和其 S 类型字段持有的引用的生命周期关联起来。
我们之前展示过函数的签名如何明确表达出它对我们传给它的引用做了什么。现在我们在类型方面展示了类似的做法:类型的生命周期参数总会揭示它是否包含某些值得关心其生命周期的引用(也就是非 'static 的)以及这些生命周期可以是什么。
假设我们有一个解析函数,它会接受一个字节切片并返回一个存有解析结果的结构:
fn parse_record<'i>(input: &'i [u8]) -> Record<'i> { ... }
不用看 Record 类型的定义就可以知道,如果从 parse_record 接收到 Record,那么它包含的任何引用就必然指向我们传入的输入缓冲区,而不是其他地方( 'static 静态值除外)。
事实上,Rust 要求包含引用的类型都要接受显式生命周期参数就是为了明示这种内部行为。其实 Rust 原本可以简单地为结构体中的每个引用创建一个不同的生命周期,从而省去把它们写出来的麻烦。实际上,Rust 的早期版本就是这么做的,但开发人员发现这样会令人困惑:了解“某个值是从另一个值中借用出来的”这一点很有帮助,特别是在处理错误时。
不仅像 S 这样的引用和类型有生命周期,Rust 中的每个类型都有生命周期,包括 i32 和 String。它们大多数是 'static 的,这意味着这些类型的值可以一直存续下去,例如, Vec<i32> 是自包含的,在任何特定变量超出作用域之前都不需要丢弃它。但是像 Vec<&'a i32> 这样的类型,其生命周期就必须被 'a 涵盖,也就是说必须在引用目标仍然存续的情况下丢弃它。
5.3.6 不同的生命周期参数
假设你已经定义了一个包含两个引用的结构体,如下所示:
struct S<'a> {
x: &'a i32,
y: &'a i32
}
这两个引用使用相同的生命周期 'a。如果这样写代码,那么可能会有问题:
let x = 10;
let r;
{
let y = 20;
{
let s = S { x: &x, y: &y };
r = s.x;
}
}
println!("{}", r);
上述代码不会创建任何悬空指针。对 y 的引用会保留在 s 中,它会在 y 之前超出作用域。对 x 的引用最终会出现在 r 中,它的生命周期不会超出 x。
然而,如果你尝试编译这段代码,那么 Rust 会报错说 y 的存活时间不够长,但其实它看起来是足够长的。为什么 Rust 会担心呢?如果仔细阅读代码,就能明白其推理过程。
S的两个字段是具有相同生命周期'a的引用,因此 Rust 必须找到一个同时适合s.x和s.y的生命周期。- 赋值
r = s.x,这就要求'a涵盖r的生命周期。 - 用
&y初始化s.y,这就要求'a不能长于y的生命周期。
这些约束是不可能满足的:没有哪个生命周期比 y 短但比 r 长。Rust 被迫止步于此。
出现这个问题是因为 S 中的两个引用具有相同的生命周期 'a。只要更改 S 的定义,让每个引用都有各自的生命周期,就可以解决所有问题:
struct S<'a, 'b> {
x: &'a i32,
y: &'b i32
}
根据这个定义, s.x 和 s.y 具有独立的生命周期。对 s.x 所做的操作不会影响 s.y 中存储的内容,因此现在很容易满足约束条件: 'a 可以用 r 的生命周期,而 'b 可以用 s 的生命周期。(虽然 'b 也可以用 y 的生命周期,但 Rust 会尝试选择可行的最小生命周期。)一切都好起来了。
函数签名也有类似的情况。假设有这样一个函数:
fn f<'a>(r: &'a i32, s: &'a i32) -> &'a i32 { r } // 可能过于严格
在这里,两个引用参数使用了相同的生命周期 'a,这可能会给调用者施加不必要的限制,就像前面讲过的那样。如果这确实是问题,可以让各个参数的生命周期独立变化:
fn f<'a, 'b>(r: &'a i32, s: &'b i32) -> &'a i32 { r } // 宽松多了
这样做的缺点是,添加生命周期会让类型和函数签名更难阅读。我们(本书作者)倾向于先尝试尽可能简单的定义,然后放宽限制,直到代码能编译通过为止。由于 Rust 不允许不安全的代码运行,因此简单地等到报告问题时再修改也是一种完全可以接受的策略。
5.3.7 省略生命周期参数
迄今为止,本书已经展示了很多返回引用或以引用为参数的函数,但通常没必要详细说明每个生命周期。生命周期就在那里,如果它们显而易见,那么 Rust 就允许我们省略。
在最简单的情况下,你可能永远不需要为参数写出生命周期。Rust 会为需要生命周期的每个地方分配不同的生命周期。例如:
struct S<'a, 'b> {
x: &'a i32,
y: &'b i32
}
fn sum_r_xy(r: &i32, s: S) -> i32 {
r + s.x + s.y
}
此函数的签名是以下代码的简写形式:
fn sum_r_xy<'a, 'b, 'c>(r: &'a i32, s: S<'b, 'c>) -> i32
如果确实要返回引用或其他带有生命周期参数的类型,那么针对无歧义的情况,Rust 会尽量采用简单的设计。如果函数的参数只有一个生命周期,那么 Rust 就会假设返回值具有同样的生命周期:
fn first_third(point: &[i32; 3]) -> (&i32, &i32) {
(&point[0], &point[2])
}
明确写出所有生命周期后的代码如下所示:
fn first_third<'a>(point: &'a [i32; 3]) -> (&'a i32, &'a i32)
如果函数的参数有多个生命周期,那么就没有理由选择某一个生命周期作为返回值的生命周期,Rust 会要求你明确指定生命周期。
但是,如果函数是某个类型的方法,并且具有引用类型的 self 参数,那么 Rust 就会假定返回值的生命周期与 self 参数的生命周期相同。( self 指的是调用方法的对象,类似于 C++、Java 或 JavaScript 中的 this 或者 Python 中的 self。9.6 节会介绍这些方法。)
例如,你可以编写以下内容:
struct StringTable {
elements: Vec<String>,
}
impl StringTable {
fn find_by_prefix(&self, prefix: &str) -> Option<&String> {
for i in 0 .. self.elements.len() {
if self.elements[i].starts_with(prefix) {
return Some(&self.elements[i]);
}
}
None
}
}
find_by_prefix 方法的签名是以下内容的简写形式:
fn find_by_prefix<'a, 'b>(&'a self, prefix: &'b str) -> Option<&'a String>
Rust 假定无论你借用的是什么,本质上都是从 self 借用的。
再次强调,这些都只是简写形式,旨在提供便利且比较直观。如果它们不是你想要的,那么你随时可以明确地写出生命周期。
5.4 共享与可变
迄今为止,本书讨论的都是 Rust 如何确保不会有任何引用指向超出作用域的变量。但是还有其他方法可能引入悬空指针。下面是一个简单的例子:
let v = vec![4, 8, 19, 27, 34, 10];
let r = &v;
let aside = v; // 把向量转移给aside
r[0]; // 错误:这里所用的`v`此刻是未初始化状态
对 aside 的赋值会移动向量、让 v 回到未初始化状态,并将 r 变为悬空指针,如图 5-7 所示。
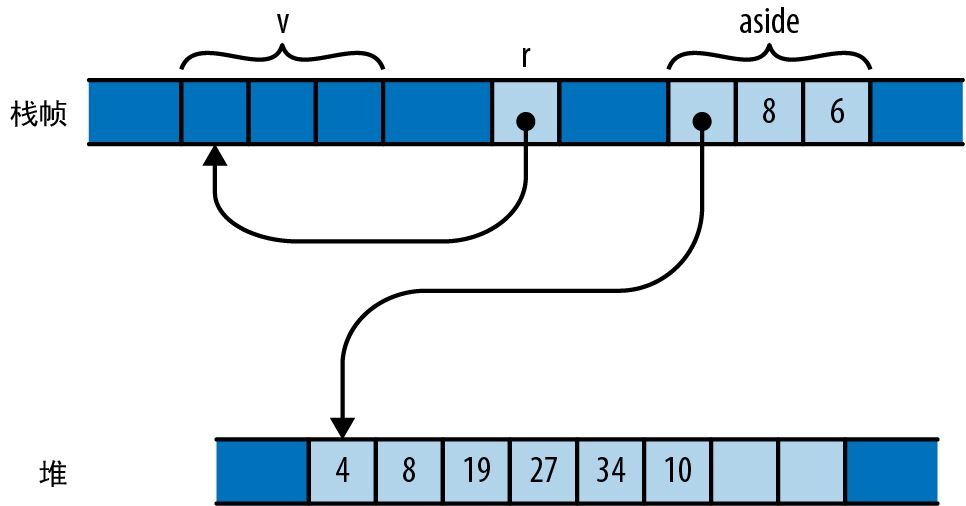
图 5-7:对已移动出去的向量的引用
尽管 v 在 r 的整个生命周期中都处于作用域内部,但这里的问题是 v 的值已经移动到别处,导致 v 成了未初始化状态,而 r 仍然在引用它。当然,Rust 会捕获错误:
error: cannot move out of `v` because it is borrowed
|
9 | let r = &v;
| - borrow of `v` occurs here
10 | let aside = v; // 把向量转移给`aside`
| ^^^^^ move out of `v` occurs here
在共享引用的整个生命周期中,它引用的目标会保持只读状态,即不能对引用目标赋值或将值移动到别处。在上述代码中, r 的生命周期内发生了移动向量的操作,Rust 当然要拒绝。如果按如下所示更改程序,就没问题了:
let v = vec![4, 8, 19, 27, 34, 10];
{
let r = &v;
r[0]; // 正确:向量仍然在那里
}
let aside = v;
在这个版本中, r 作用域范围更小,在把 v 转移给 aside 之前, r 的生命周期就结束了,因此一切正常。
下面是另一种制造混乱的方式。假设我们随手写了一个函数,它使用切片的元素来扩展某个向量:
fn extend(vec: &mut Vec<f64>, slice: &[f64]) {
for elt in slice {
vec.push(*elt);
}
}
这是标准库中向量的 extend_from_slice 方法的一个不太灵活(并且优化程度较低)的版本。可以用它从其他向量或数组的切片中构建一个向量:
let mut wave = Vec::new();
let head = vec![0.0, 1.0];
let tail = [0.0, -1.0];
extend(&mut wave, &head); // 使用另一个向量扩展`wave`
extend(&mut wave, &tail); // 使用数组扩展`wave`
assert_eq!(wave, vec![0.0, 1.0, 0.0, -1.0]);
我们在这里建立了一个正弦波周期。如果想添加另一个周期,那么可以把向量追加到其自身吗?
extend(&mut wave, &wave);
assert_eq!(wave, vec![0.0, 1.0, 0.0, -1.0,
0.0, 1.0, 0.0, -1.0]);
乍一看你可能觉得这还不错。但别忘了,在往向量中添加元素时,如果它的缓冲区已满,那么就必须分配一个具有更多空间的新缓冲区。假设开始时 wave 有 4 个元素的空间,那么当 extend 尝试添加第五个元素时就必须分配更大的缓冲区。内存最终如图 5-8 所示。
extend 函数的 vec 参数借用了 wave(由调用者拥有),而 wave 为自己分配了一个新的缓冲区,其中有 8 个元素的空间。但是 slice 仍然指向旧的 4 元素缓冲区,该缓冲区已经被丢弃了。
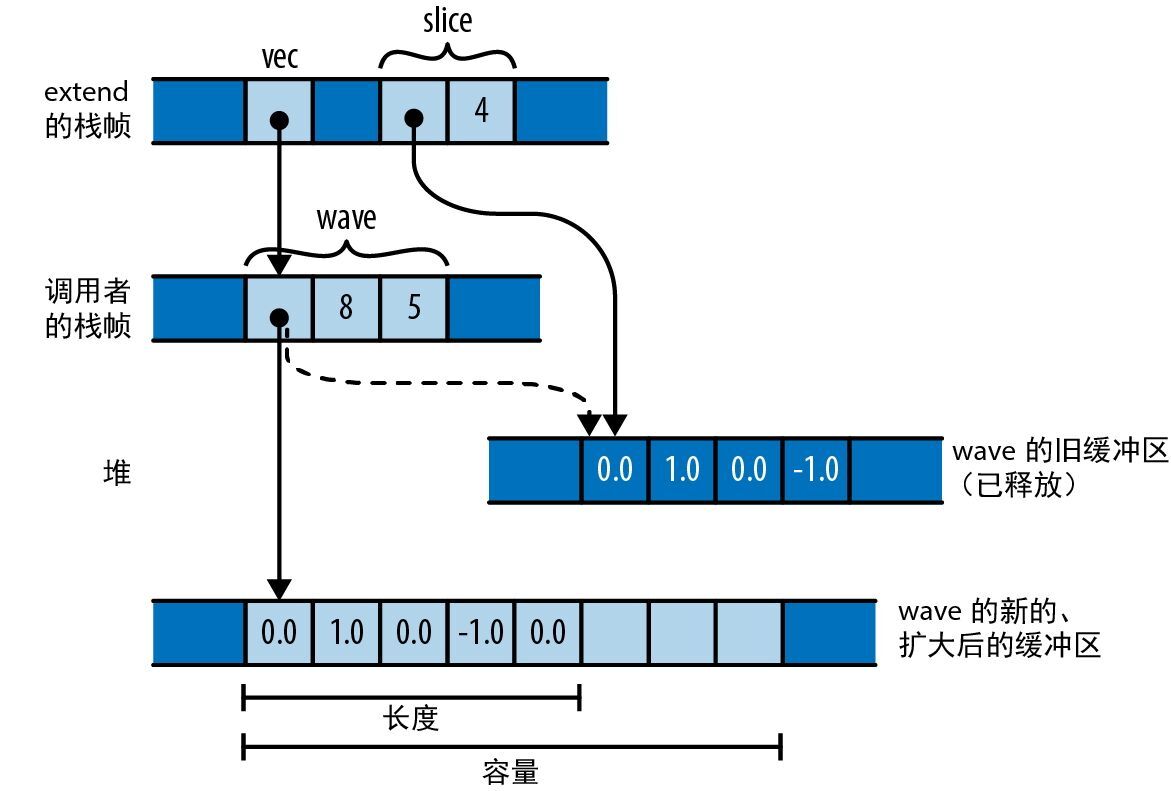
图 5-8:通过向量的重新分配将 slice 变成了悬空指针
这种问题并不是 Rust 独有的:在许多语言中,在指向集合的同时修改集合要加倍小心。在 C++ 中, std::vector 规范会告诫你“重新分配向量缓冲区会令指向序列中各个元素的所有引用、指针和迭代器失效”。Java 对修改 java.util.Hashtable 对象也有类似的说法。
如果在创建迭代器后的任何时间以任何方法(迭代器自身的
remove方法除外)修改了Hashtable的结构,那么迭代器都将抛出ConcurrentModificationException异常。
这类错误特别难以调试,因为它只会偶尔发生。在测试中,向量可能总是恰好有足够的空间,缓冲区可能永远都不会重新分配,于是这个问题可能永远都没人发现。
然而,Rust 会在编译期报告调用 extend 有问题:
error: cannot borrow `wave` as immutable because it is also
borrowed as mutable
|
9 | extend(&mut wave, &wave);
| ---- ^^^^- mutable borrow ends here
| | |
| | immutable borrow occurs here
| mutable borrow occurs here
换句话说,我们既可以借用向量的可变引用,也可以借用其元素的共享引用,但这两种引用的生命周期不能重叠。在这个例子中,这两种引用的生命周期都包含着对 extend 的调用,出现了重叠,因此 Rust 会拒绝执行这段代码。
这些错误都源于违反了 Rust 的“可变与共享”规则。
共享访问是只读访问。
共享引用借用的值是只读的。在共享引用的整个生命周期中,无论是它的引用目标,还是可从该引用目标间接访问的任何值,都不能被 任何代码 改变。这种结构中不能存在对任何内容的有效可变引用,其拥有者应保持只读状态,等等。值完全冻结了。
可变访问是独占访问。
可变引用借用的值只能通过该引用访问。在可变引用的整个生命周期中,无论是它的引用目标,还是该引用目标间接访问的任何目标,都没有任何其他路径可访问。对可变引用来说,唯一能和自己的生命周期重叠的引用就是从可变引用本身借出的引用。
Rust 报告说 extend 示例违反了第二条规则:因为我们借用了对 wave 的可变引用,所以该可变引用必须是抵达向量或其元素的唯一方式。而对切片的共享引用本身是抵达这些元素的另一种方式,这违反了第二条规则。
但是 Rust 也可以将我们的错误视为违反了第一条规则:因为我们借用了对 wave 元素的共享引用,所以这些元素和 Vec 本身都是只读的。不能对只读值借用出可变引用。
每种引用都会影响到我们可以对“到引用目标从属路径上的值”以及“从引用目标可间接访问的值”所能执行的操作,如图 5-9 所示。
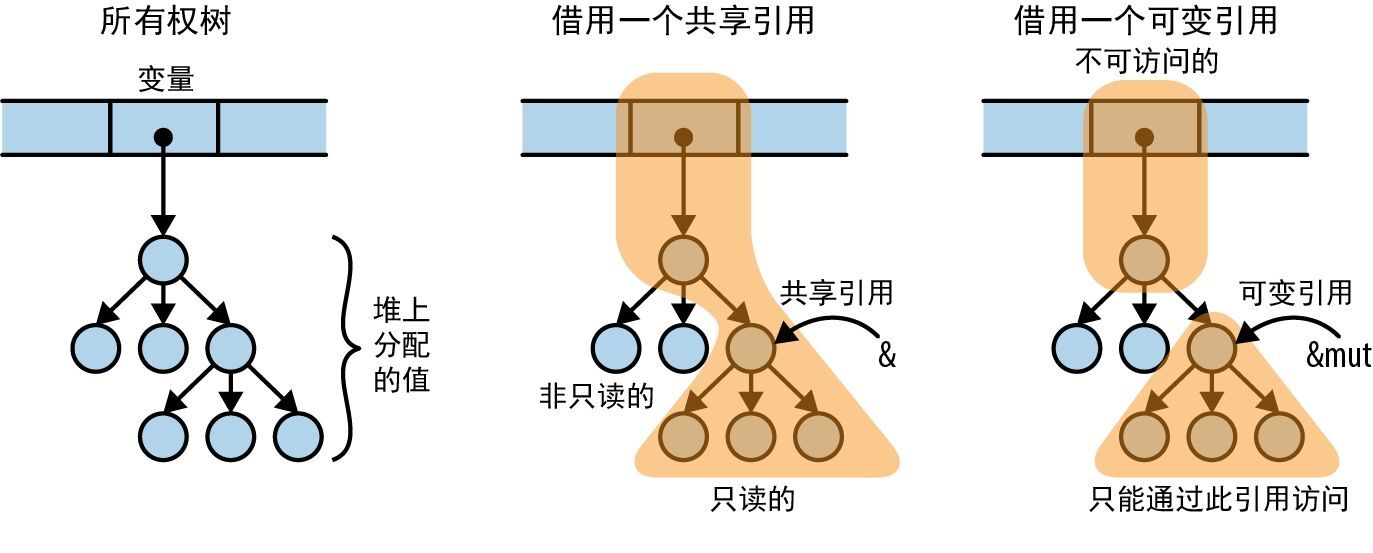
图 5-9:借用引用会影响你对同一所有权树中的其他值执行的操作
请注意,在这两种情况下,指向引用目标的所有权路径在此引用的生命周期内都无法更改。对于共享借用,这条路径是只读的;对于可变借用,这条路径是完全不可访问的。所以程序无法做出任何会使该引用无效的操作。
可以将这些原则分解为一些最简单的示例:
let mut x = 10;
let r1 = &x;
let r2 = &x; // 正确:允许多个共享借用
x += 10; // 错误:不能赋值给`x`,因为它已被借出
let m = &mut x; // 错误:不能把`x`借入为可变引用,因为
// 它涵盖在已借出的不可变引用的生命周期内
println!("{}, {}, {}", r1, r2, m); // 这些引用是在这里使用的,所以它们
// 的生命周期至少要存续这么长
let mut y = 20;
let m1 = &mut y;
let m2 = &mut y; // 错误:不能多次借入为可变引用
let z = y; // 错误:不能使用`y`,因为它涵盖在已借出的可变引用的生命周期内
println!("{}, {}, {}", m1, m2, z); // 在这里使用这些引用
可以从共享引用中重新借入共享引用:
let mut w = (107, 109);
let r = &w;
let r0 = &r.0; // 正确:把共享引用重新借入为共享引用
let m1 = &mut r.1; // 错误:不能把共享引用重新借入为可变
println!("{}", r0); // 在这里使用r0
可以从可变引用中重新借入可变引用:
let mut v = (136, 139);
let m = &mut v;
let m0 = &mut m.0; // 正确: 从可变引用中借入可变引用
*m0 = 137;
let r1 = &m.1; // 正确: 从可变引用中借入共享引用,并且不能和m0重叠
v.1; // 错误:禁止通过其他路径访问
println!("{}", r1); // 可以在这里使用r1
这些限制非常严格。回过头来看看我们尝试调用 extend(&mut wave, &wave) 的地方,没有什么快速而简便的方法来修复代码,以使其按照我们想要的方式工作。Rust 中到处都在应用这些规则:如果要借用对 HashMap 中键的共享引用,那么在共享引用的生命周期结束之前就不能再借入对 HashMap 的可变引用。
但这么做有充分的理由:要为集合设计出“支持不受限制地在迭代期间修改”的能力是非常困难的,而且往往会导致无法简单高效地实现这些集合。Java 的 Hashtable 和 C++ 的 vector 就不支持这种访问方式,Python 的字典和 JavaScript 的对象甚至都不曾定义过这种访问方式。JavaScript 中的其他集合类型固然可以做到,不过需要更繁重的实现。C++ 的 std::map 承诺插入新条目不会让指向此映射表中其他条目的指针失效,但做出这一承诺的代价是该标准无法提供像 Rust 的 BTreeMap 这样更高效的缓存设计方案,因为后者会在树的每个节点中存储多个条目。
下面是通过上述规则捕获各种错误的另一个例子。考虑以下 C++ 代码,它用于管理文件描述符。为了简单起见,这里只展示一个构造函数和复制赋值运算符,并会省略错误处理代码:
struct File {
int descriptor;
File(int d) : descriptor(d) { }
File& operator=(const File &rhs) {
close(descriptor);
descriptor = dup(rhs.descriptor);
return *this;
}
};
这个赋值运算符很简单,但在下面这种情况下会执行失败:
File f(open("foo.txt", ...));
...
f = f;
如果将一个 File 赋值给它自己,那么 rhs 和 *this 就是同一个对象,所以 operator= 会关闭它要传给 dup 的文件描述符。也就是说,我们销毁了正打算复制的那份资源。
在 Rust 中,类似的代码如下所示:
struct File {
descriptor: i32
}
fn new_file(d: i32) -> File {
File { descriptor: d }
}
fn clone_from(this: &mut File, rhs: &File) {
close(this.descriptor);
this.descriptor = dup(rhs.descriptor);
}
(这并不是 Rust 的惯用法。有很多很好的方式可以让 Rust 类型拥有自己的构造函数和方法,第 9 章会对此进行讲解,刚才的定义方式仅仅是为了示范。)
如果编写使用了 File 的 Rust 代码,就会得到如下内容:
let mut f = new_file(open("foo.txt", ...));
...
clone_from(&mut f, &f);
当然,Rust 干脆拒绝编译这段代码:
error: cannot borrow `f` as immutable because it is also
borrowed as mutable
|
18 | clone_from(&mut f, &f);
| - ^- mutable borrow ends here
| | |
| | immutable borrow occurs here
| mutable borrow occurs here
以上错误看起来很熟悉。事实证明,这里的两个经典 C++ 错误(无法处理自赋值和使用无效迭代器)本质上是同一种错误。在这两种情况下,代码都以为自己正在修改一个值,同时在引用另一个值,但实际上两者是同一个值。如果你不小心让调用 memcpy 或 strcpy 的源和目标在 C 或 C++ 中重叠,则可能会带来另一种错误。通过要求可变访问必须是独占的,Rust 避免了一大类日常错误。
在编写并发代码时,共享引用和可变引用的互斥性确实证明了其价值。只有当某些值既可变又要在线程之间共享时,才可能出现数据竞争,而这正是 Rust 的引用规则所要消除的。一个用 Rust 编写的并发程序,只要避免使用 unsafe 代码,就可以 在构造之初就避免 产生数据竞争。第 19 章在讨论并发时会更详细地对此进行介绍。总而言之,与大多数其他语言相比,并发在 Rust 中更容易使用。
Rust 的共享引用与 C 的 const 指针
乍一看,Rust 的共享引用似乎与 C 和 C++ 中指向
const值的指针非常相似。然而,Rust 中共享引用的规则要严格得多。例如,考虑以下 C 代码:int x = 42; // int变量,不是常量 const int *p = &x; // 指向const int的指针 assert(*p == 42); x++; // 直接修改变量 assert(*p == 43); //“常量”指向的值发生了变化
p是const int *这一事实意味着不能通过p本身修改它的引用目标,也就是说,禁止使用(*p)++。但是可以直接通过x获取引用目标,x不是const,能以这种方式更改其值。C 家族的const关键字自有其用处,但与“常量”无关。在 Rust 中,共享引用禁止对其引用目标进行任何修改,直到其生命周期结束:
let mut x = 42; // 非常量型i32变量 let p = &x; // 到i32的共享引用 assert_eq!(*p, 42); x += 1; // 错误:不能对x赋值,因为它已被借出 assert_eq!(*p, 42); // 如果赋值成功,那么这应该是true为了保证一个值是常量,需要追踪该值的所有可能路径,并确保它们要么不允许修改,要么根本不能使用。C 和 C++ 的指针不受限制,编译器无法对此进行检查。Rust 的引用总是与特定的生命周期相关联,因此可以在编译期检查它们。
5.5 应对复杂对象关系
自 20 世纪 90 年代自动内存管理兴起以来,所有程序都由大量复杂关联的对象构成,如图 5-10 所示。
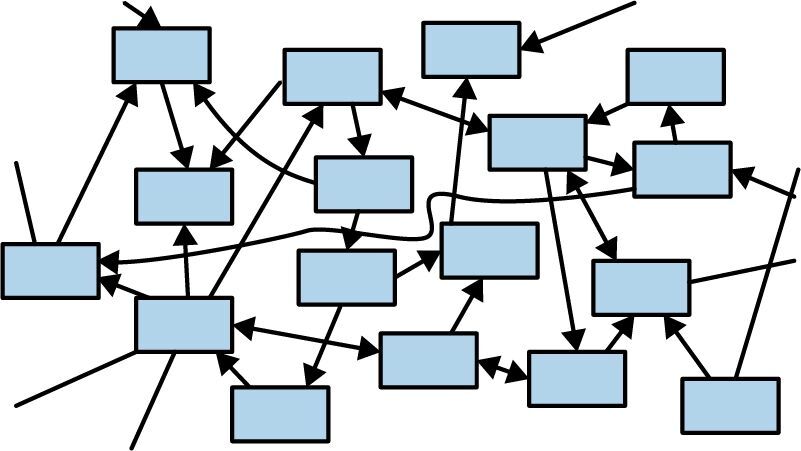
图 5-10:复杂对象关系
如果你采用垃圾回收(自动内存管理)并且在开始编写程序之前不做任何设计,就会发生这种情况。我们都构建过这样的系统。
这种架构有很多从图 5-10 中无法看出的优点:初始的进展迅速;很容易添加新功能;几年以后,你将很容易确定你需要完全重写它。(让我们来一首澳大利亚摇滚乐队 AC/DC 的“通往地狱的高速公路”。2)
当然,这种架构也有缺点。当每个部分都像这样依赖于其他部分时,必然很难测试、迭代,甚至很难单独考虑其中的任何组件。
Rust 令人着迷的地方之一就在于,其所有权模型就好像是在通向地狱的高速公路上铺设了一条减速带。在 Rust 中创建循环引用(两个值,每个值都包含指向另一个值的引用)相当困难。你必须使用智能指针类型(如 Rc)和内部可变性(目前为止本书还未涉及这个主题)。Rust 更喜欢让指针、所有权和数据流单向通过系统,如图 5-11 所示。
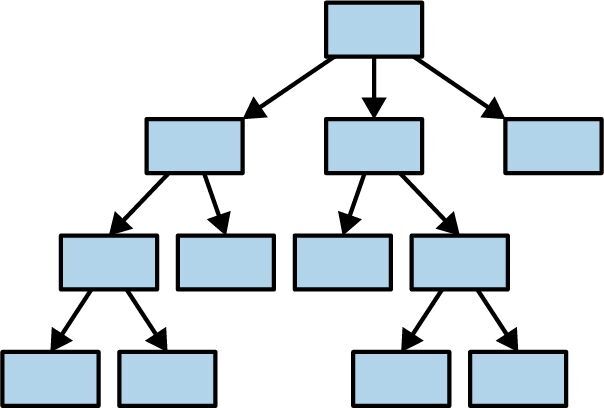
图 5-11:树形对象关系
之所以现在提出这个问题,是因为在阅读本章后,你可能会很自然地想要立即编写代码并创建出大量的对象,所有对象之间使用 Rc 智能指针关联起来,最终呈现你熟悉的所有面向对象反模式。但此刻这还行不通。Rust 的所有权模型会不断给你制造麻烦。解决之道是进行一些前期设计并构建出更好的程序。
Rust 就是要把你理解程序的痛苦从将来移到现在。它确实做到了:Rust 不仅会迫使你理解为什么自己的程序是线程安全的,甚至可能还需要你做一些高级架构设计。